Sim-to-Real Reinforcement Learning für einen 7-DOF Weltraummanipulator
Vom Training zur Hardwareübertragung auf den Kinova Gen3
Steven Patrick Ermisch · Matrikelnr. 1447361
Bachelorarbeit · B.Eng. Mechatronik
Frankfurt University of Applied Sciences
Referent: Prof. Dr.-Ing. Eric Guiffo Kaigom
Korreferent: M.Sc. Patrick Oberdörfer
Abgabedatum: 1. Mai 2026
Inhaltsverzeichnis
Einleitung
01 · Motivation & Kontext
02 · Forschungsfrage & Beiträge
03 · Vom 4-DOF zum 7-DOF
Grundlagen
04 · SpaceKinova-System
05 · Free-Floating-Dynamik
Modellierung
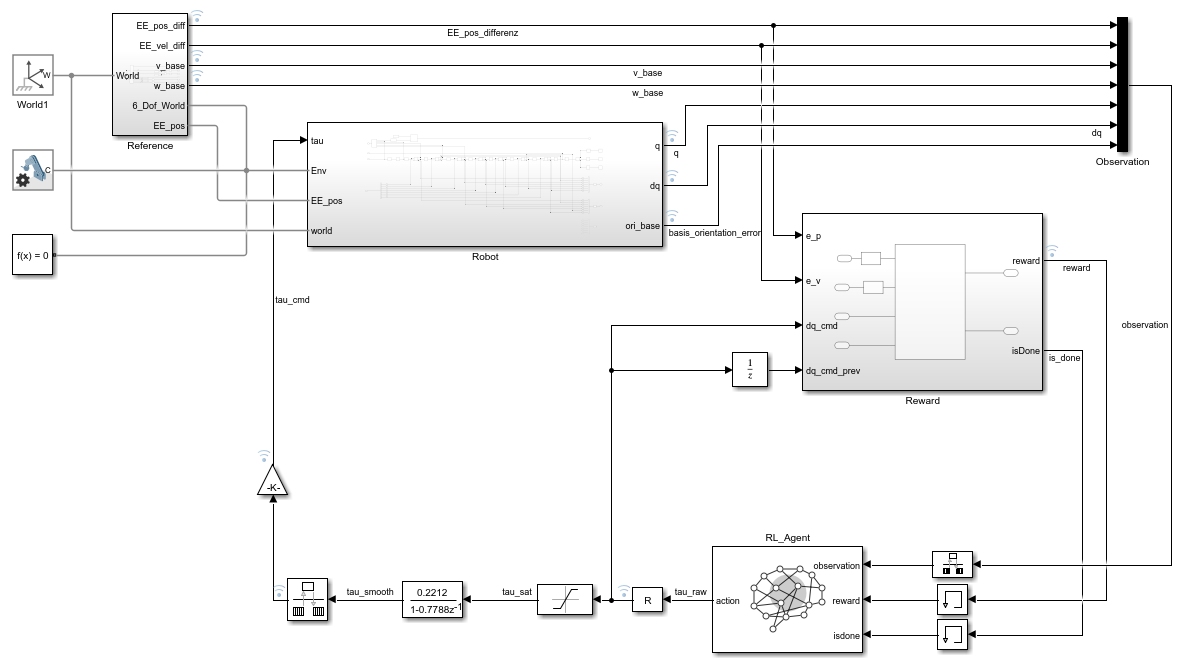
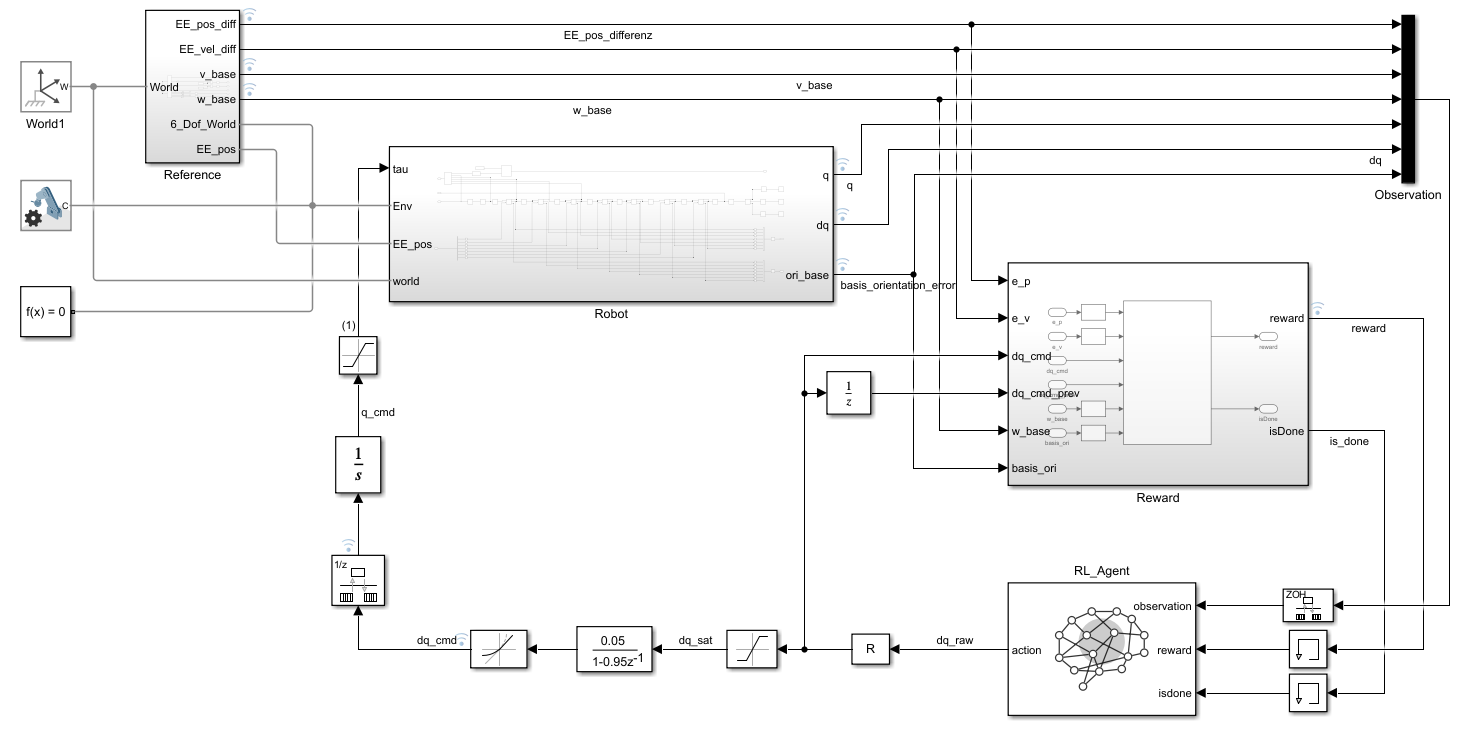
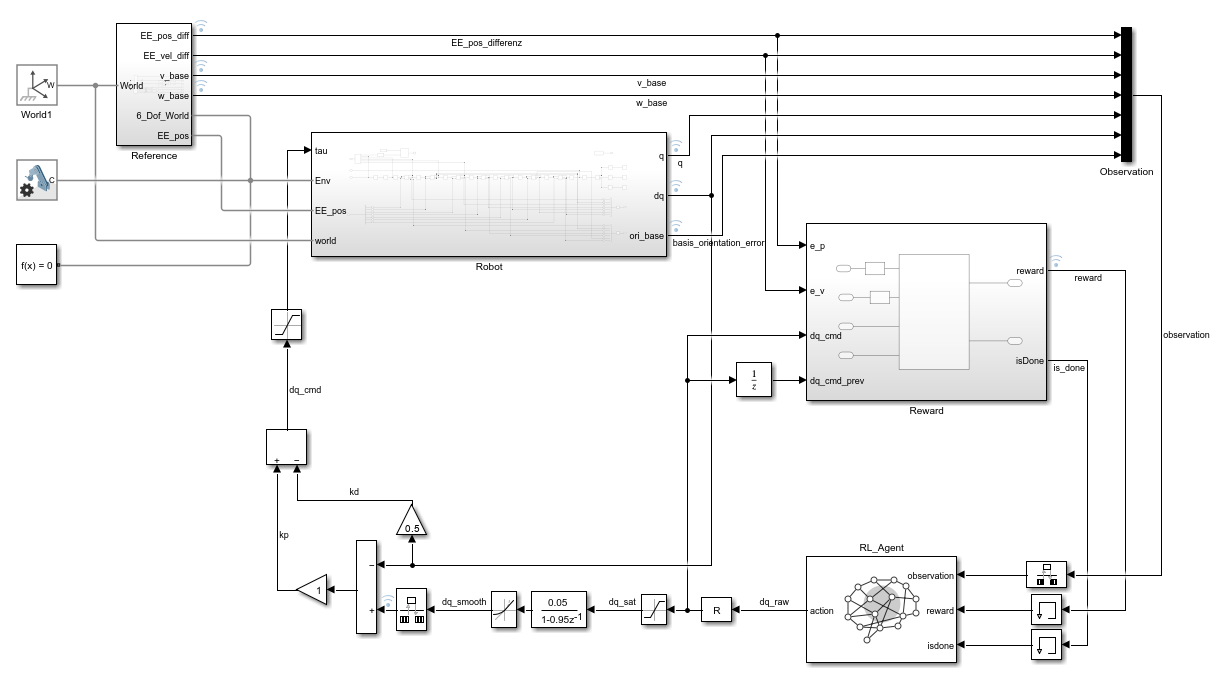
06 · Simulink – Vergleich
07–09 · Simulink-Overviews
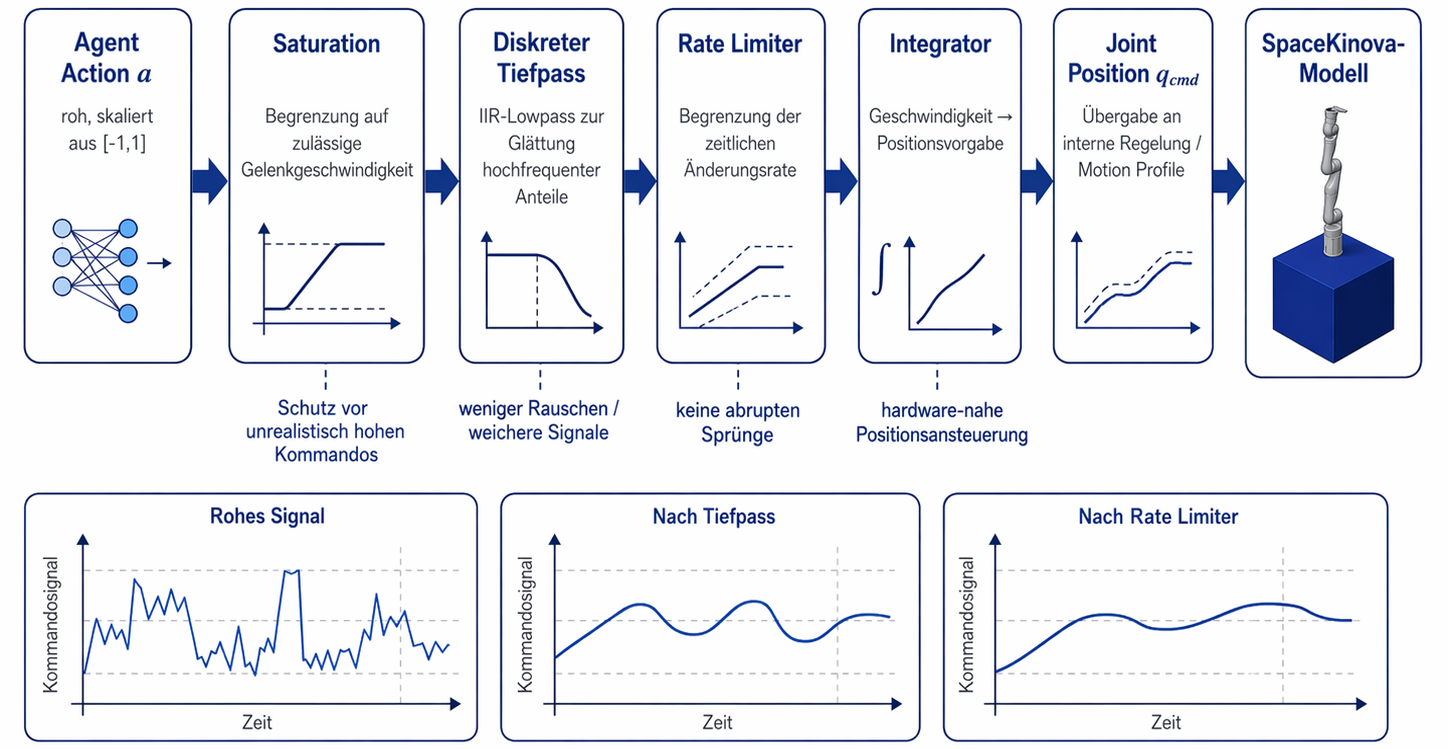
10 · Glättung & 40 Hz-Bridge
RL-Framework
11 · Observation, Action & PPO-Netz
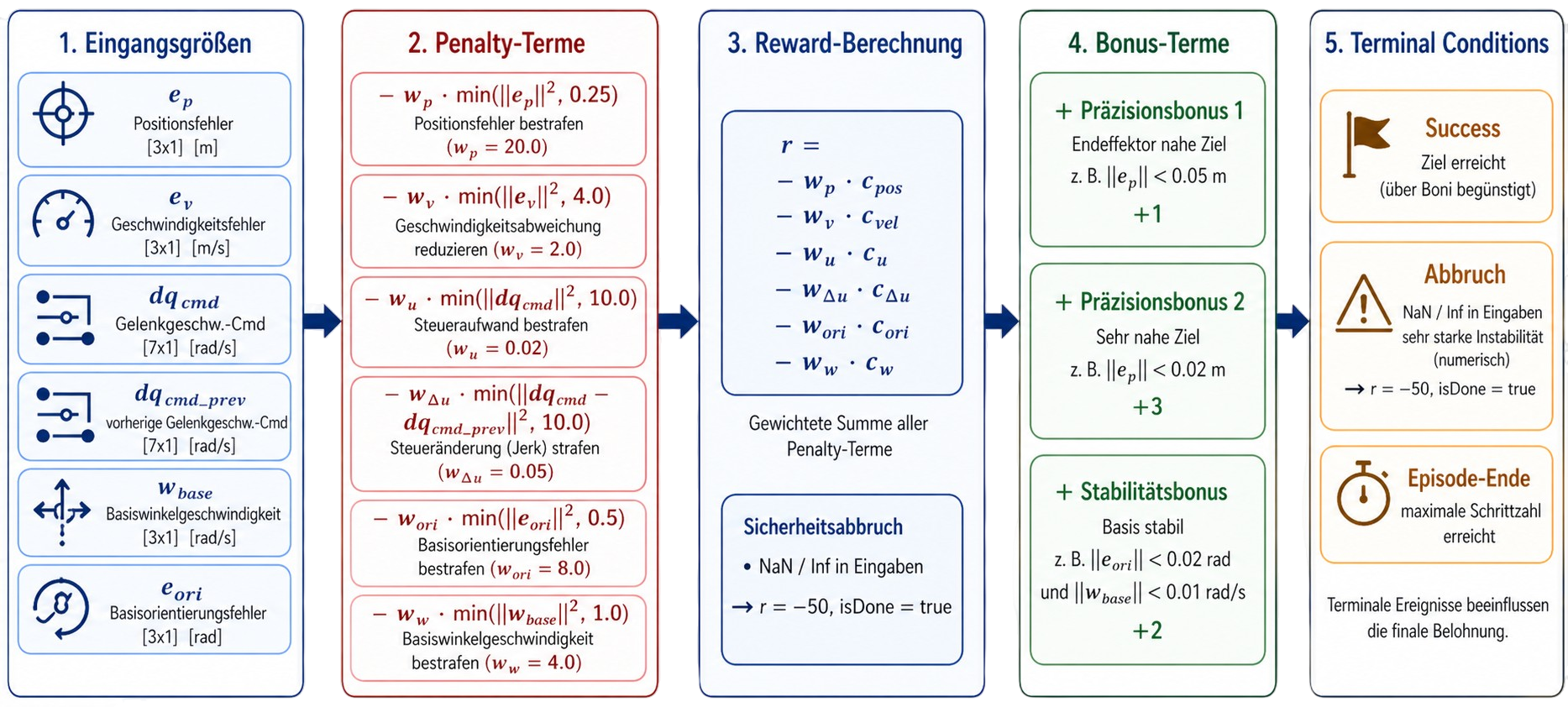
12 · Reward-Funktion
13 · Bayes-HPO
Sim-to-Real
14 · Curriculum DR
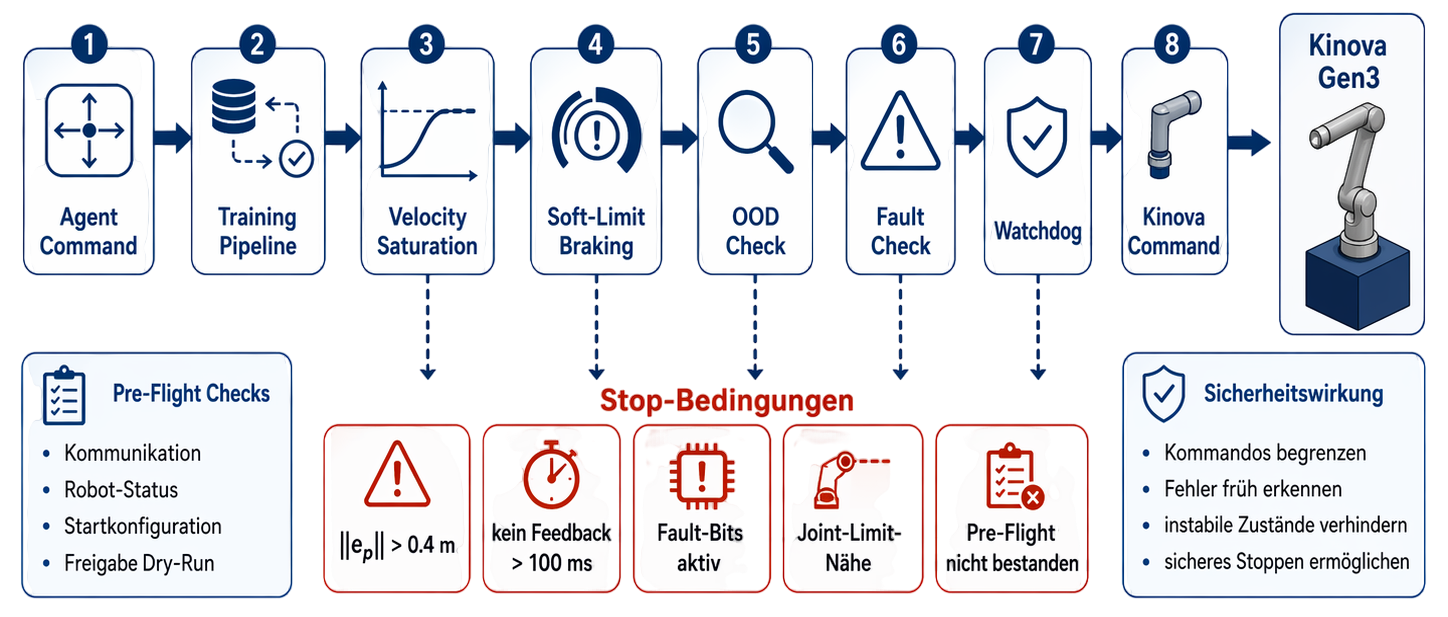
15 · Sicherheitskonzept
16 · Hardware-Setup
Ergebnisse
18 · Algorithmenvergleich
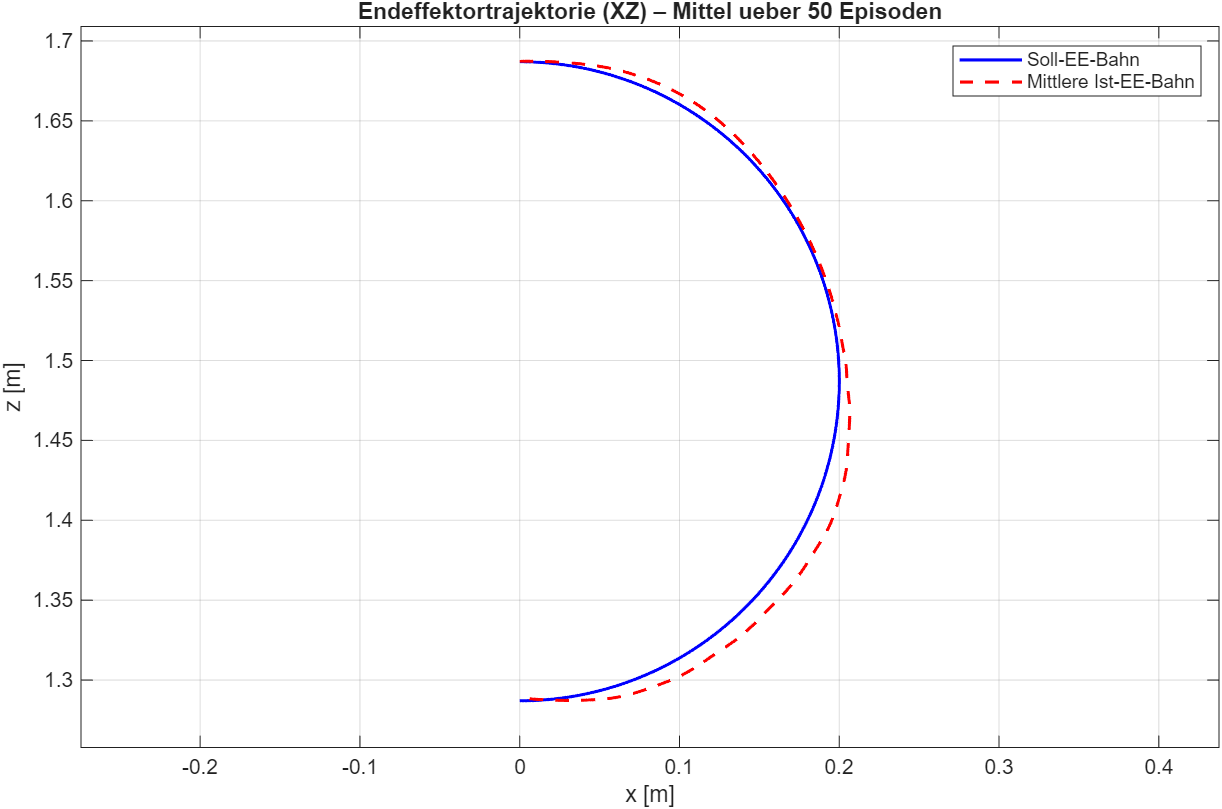
19 · PPO & Bahnverfolgung
20 · CDR-Robustheit
21 · HW Open-Loop-Test
22 · Sample-Rate-Mismatch
Fazit
23 · Zusammenfassung
24 · Ausblick
Einleitung
Motivation, Forschungsfrage & Ausgangslage
Motivation & Kontext
On-Orbit-Servicing
Inspektion, Wartung und Bergung von Satelliten verlangt autonome Manipulatoren
auf frei schwebenden Trägern. Missionen wie ClearSpace-1 setzen diesen Trend.
Herausforderung Sim-to-Real
Tests im Orbit nicht wiederholbar, nicht bezahlbar
Bodentests ohne Gravitation kaum nachstellbar
Klassische Regelung: Modellwissen + Tuning pro Missionsszenario
Transferlücke zwischen idealer Simulation und realer Hardware
Lösungsansatz dieser Arbeit
RL-Agent in Simulink trainieren · Curriculum Domain Randomization gegen die
Reality-Gap · formale Safety-Schicht für den Transfer auf den realen Kinova Gen3.
Abb.: On-Orbit-Servicing-Szenario (Weltraummanipulator an Zielsatellit)
Forschungsfrage & Beiträge
„Wie lässt sich ein RL-Agent für einen 7-DOF-Manipulator auf einer frei schwebenden Basis
so trainieren und absichern, dass er nach einem domänenrandomisierten Training
auf die reale Kinova Gen3 übertragbar ist -
ohne externe Regelung und mit minimaler Basisdrift?"
🎓 Curriculum DR
5 Randomisierungs-Features in 4 Phasen · gestaffelte Schwierigkeit statt
„alles auf einmal".
🔬 Bayes-Fund
Asymmetrische Lernraten · Critic:Actor ≈ 17 : 1 · identifiziert durch
20 Trials / 12 h Bayes-Opt.
🛡️ Hardware-Bridge
MEX-Interface @ 40 Hz + mehrstufiges Sicherheitskonzept als
formale Transfer-Schicht zur realen Kinova.
Vom 4-DOF-Vorgänger zum 7-DOF-Ziel
Ausgangspunkt: Mechatronikprojekt
4-DOF-Roboterarm auf Würfelbasis
Kreisbahn r = 0,4 m, T = 8,5 s
PPO als Referenzagent identifiziert
Simulation-only, keine Hardwarekopplung
Neue Herausforderungen 7-DOF
Höherdimensionaler Aktions- und Zustandsraum
Redundante Nullspace-Konfigurationen
Reale Hardware: Aktuatorträgheit, Delays, Reibung
Sim-to-Real-Lücke & Safety gegenüber Mensch/Setup
Transfer dieser Arbeit
→ Diese Arbeit skaliert den bewährten
PPO-Kern auf 7 DOF und ergänzt Curriculum DR sowie eine Hardware-Bridge. Hinweis: Kein A/B-Vergleich — Aktionsraum, Frequenz und Trajektorie wurden gleichzeitig variiert.
Altes 4-DOF-Modell · feste Basis
Neues Kinova-Modell · 7 DOF · feste Basis
Grundlagen
SpaceKinova & Free-Floating-Dynamik
SpaceKinova – Der 7-DOF-Weltraummanipulator
7Gelenke
6Basis-DOF
13DOF gesamt
Kinova Gen3 Ultra-Lightweight
Kommerzieller 7-DOF-Manipulator · Harmonic-Drive-Gelenke mit
integrierter Sensorik · Torque-Sense an allen Achsen ·
ROS/Kortex-API für Low-Level-Zugriff.
Würfelförmige Schwerelos-Basis
1 × 1 × 1 m, 65 kg, Idiag = 10,833 kg·m² ·
frei schwebend · keine Gravitation, keine Thruster → reine Impulserhaltung bestimmt
die Basisbewegung.
Sim-/Hardware-Setup
Simulation mit Simscape Multibody, URDF-basiert, Solver
ode14x @ 0,005 s · Hardware-Seite: Kortex-API über
MEX-Interface @ 40 Hz.
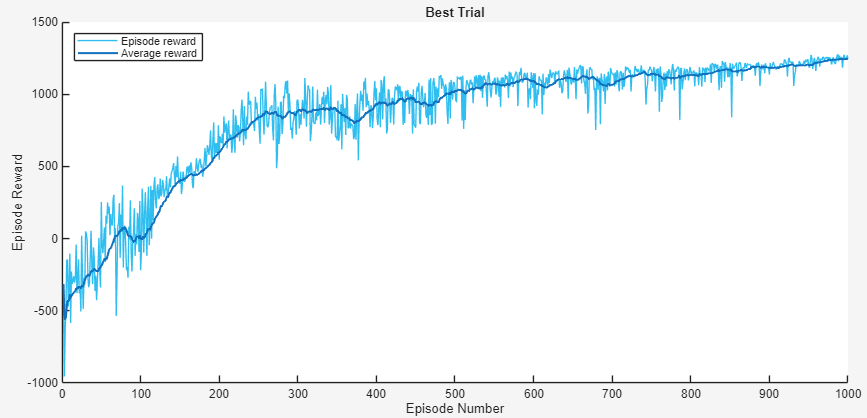
Der Critic braucht eine deutlich höhere Lernrate als der Actor: beste Konfiguration bei ≈ 17 : 1.
Triangle: 224,6 → 1244 (≈ 5,5×). Halfcircle-Werte sind nicht direkt vergleichbar.
Best Score pro Trial (17 abgeschlossene Trials)
Sim-to-Real-Pipeline
Curriculum Domain Randomization & Sicherheit
Curriculum Domain Randomization (CDR)
Vier modulare Randomisierungs-Features werden über vier Curriculum-Phasen gestaffelt aktiviert: jede Phase baut auf der vorherigen auf. CDR-1 Trajektorien (6 Bahnformen) ·
CDR-2 Basis-Masse/Trägheit ·
CDR-3 Aktuator-Delay ·
CDR-4 Gelenkreibung & Dämpfung.
1500 Episoden = 4 Phasen × 5 Sub-Batches × 75Persistenter PPO-Agent über alle PhasenFast-Restart innerhalb der Sub-Batches
Mehrstufiges Sicherheitskonzept
Safety lebt zwischen Policy und KinovaPolicy bleibt austauschbarSim und Real nutzen dieselben Gates
Hardware-Setup
Ergebnisse
Algorithmen, PPO-Training & Robustheit
Algorithmenvergleich (Simulation, 7-DOF, Phase 1)
KPI
PG
TRPO
DDPG
TD3
SAC
PPO
K1 EE-MSE [m²]
0,0502
0,0016
0,0050
0,0507
0,0513
0,0015
K2 Max-Tracking [m]
0,5165
0,1439
0,1616
0,5094
0,5156
0,1866
K3 Basis-Orient. [rad]
0,0737
0,0215
0,0483
0,0602
0,0489
0,0169
K4 Basis-ω [rad/s]
0,0525
0,0128
0,0099
0,0548
0,0463
0,0078
K5 Leistung [W]
0,0969
0,0765
0,1324
0,0808
0,0400
0,0920
K6 Jerk [–]
0,0451
0,0228
0,0495
0,0021
0,0110
0,0515
K7 Return [–]
−185,1
515,4
296,6
−66,9
−80,2
638,8
K8 ET-Rate [0…1]
1,0
0
0
1,0
1,0
0
K9 Abbruch [s]
3,42
8,50
8,50
2,83
2,89
8,50
Fazit: PPO erzielt in 6 von 9 KPIs den besten Wert · MSE = 0,0015 m² · Return = 638,8 · ET-Rate = 0
K7 Episoden-Return im Vergleich
PPO – Lernverlauf & Bahnverfolgung
Bayes-HPO – Best-Trial-Reward
Bahnverfolgung – Evaluationslauf
0,0015MSE Halfcircle [m²]
638,8Return Default (Half)
1244Return BO (Triangle)
×5,5vs. Default Triangle
40 HzAgent-Rate
Hinweis: Default-PPO und Bayes-optimiertes PPO wurden auf unterschiedlichen Trajektorien evaluiert (Halfcircle vs. Triangle) — Returns nicht direkt vergleichbar.
CDR – Einzel-Feature-Evaluation gegen No-CDR-Baseline
Jedes Feature wurde gegen eine spezialisierte No-CDR-Baseline auf einer Out-of-Distribution-Test-Störung geprüft (Generalisierungstest, nicht In-Distribution).
KombiEffekte additiv, keine starke Superadditivität
Take-away: CDR hilft vor allem bei echter OOD-Distanz; Generalisierungstests sind aussagekräftiger als In-Distribution-Stress.
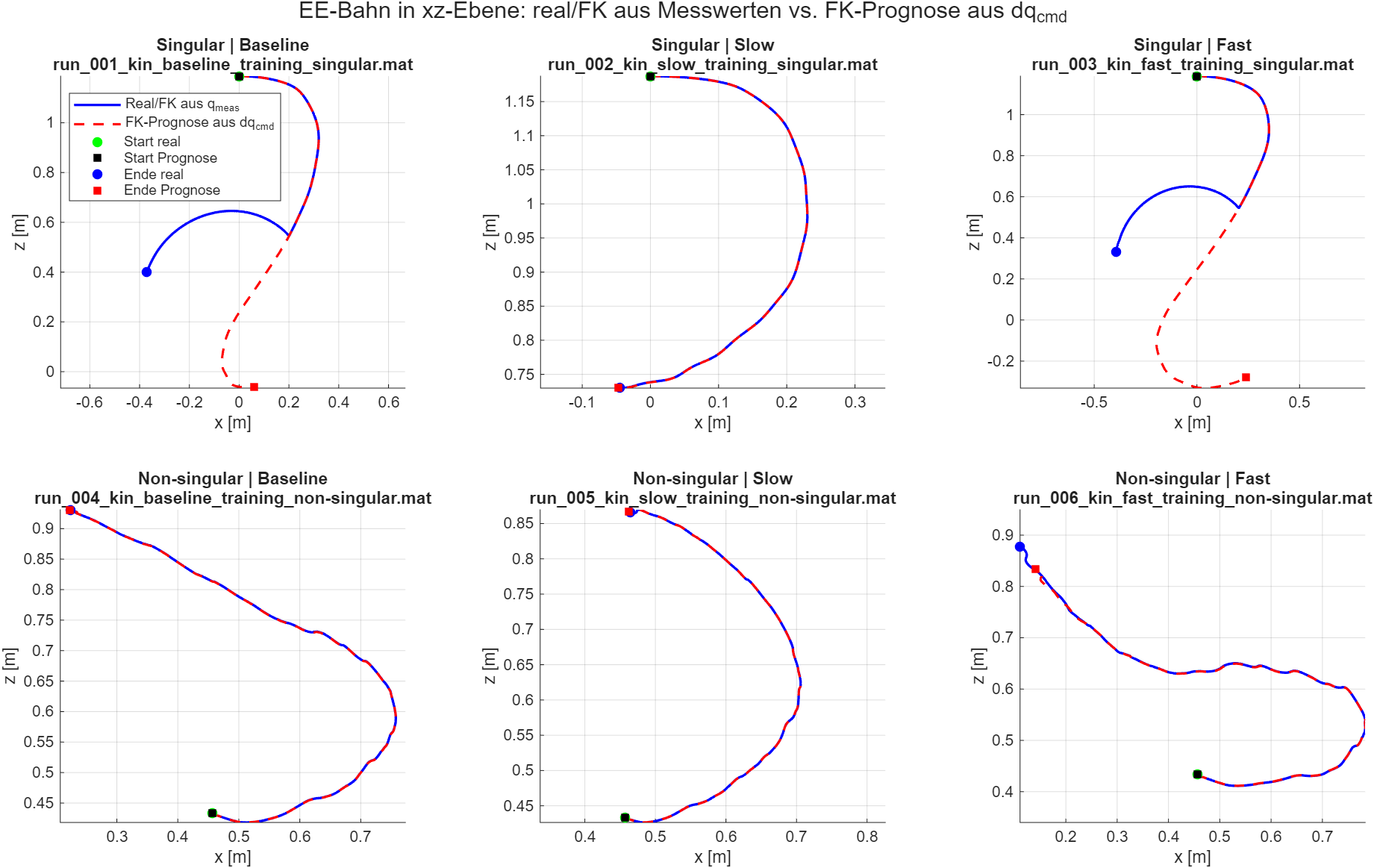
Hardware-Validierung – Open-Loop-Velocity-Test
Open-loop-Test: geloggte q̇cmd(t) aus der Simulation wird auf dem Kinova Gen3 abgespielt. Policy aus der Schleife → Hardware-Plant isoliert geprüft; 6 Läufe = 2 Startposen × 3 Zeitskalen τ.
Run-Matrix (RMS EE-Fehler real vs. FK-Vorhersage)
Datensatz
τ
RMS EE
Status
Singulär q₀=0
1,0
0,42 m
Kollision
Singulär q₀=0
2,0
1,5 mm
vollständig
Singulär q₀=0
0,75
0,57 m
Kollision
Nicht-singulär
1,0
2,6 mm
Drift J4
Nicht-singulär
2,0
1,6 mm
vollständig
Nicht-singulär
0,75
0,09 m
Kollision
τ = 2,0 läuft vollständigSingulär und nicht-singulär: 1,5–1,6 mm RMS EE.
Saturation falsifiziert25°/s → 60°/s behebt die Abbrüche nicht.
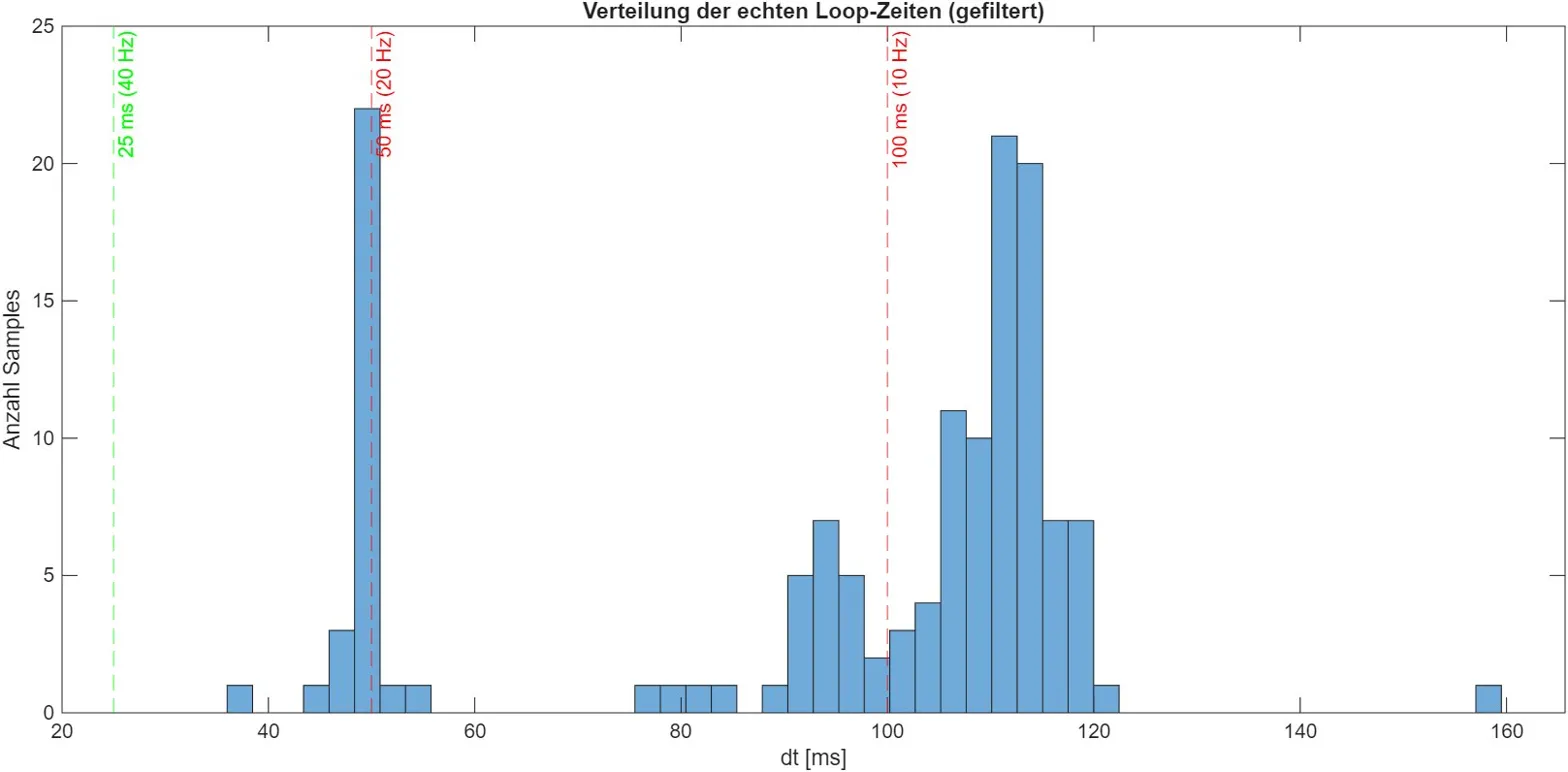
Sample-Rate-Mismatch im Closed-Loop & Workaround
Drei Hypothesen geprüft
① Velocity-Clipping (q̇max=25°/s) — falsifiziert
② Reglerbandbreite Low-Level 1 kHz — folgt sauber
③ Loop-Frequenz-Mismatch der MEX-API — bestätigt
Gemessene Loop-Zeiten
Konfiguration
Median Δt
Effektive Rate
Send-only
25,5 ms
39,2 Hz
Playback (+ Feedback + FK)
50 ms
20 Hz
Closed-Loop-Deploy
107 ms
9,3 Hz
Konsequenz: 40 Hz Soll vs. 9,3 Hz real verschiebt die Velocity-Wirkung und den IIR-Filter-Arbeitspunkt; die Solltrajektorie wird gethrottelt, ‖ep‖ wächst bis zum OOD-Stopp.
10 Hz-WorkaroundFährt vollständig, aber mit >10 cm Bahnabweichung: nur Diagnose, kein Deployment.
Praktischer BefundHigh-Level-MEX/Kortex ist effektiv 10–20 Hz; höhere Raten brauchen Low-Level-UDP.
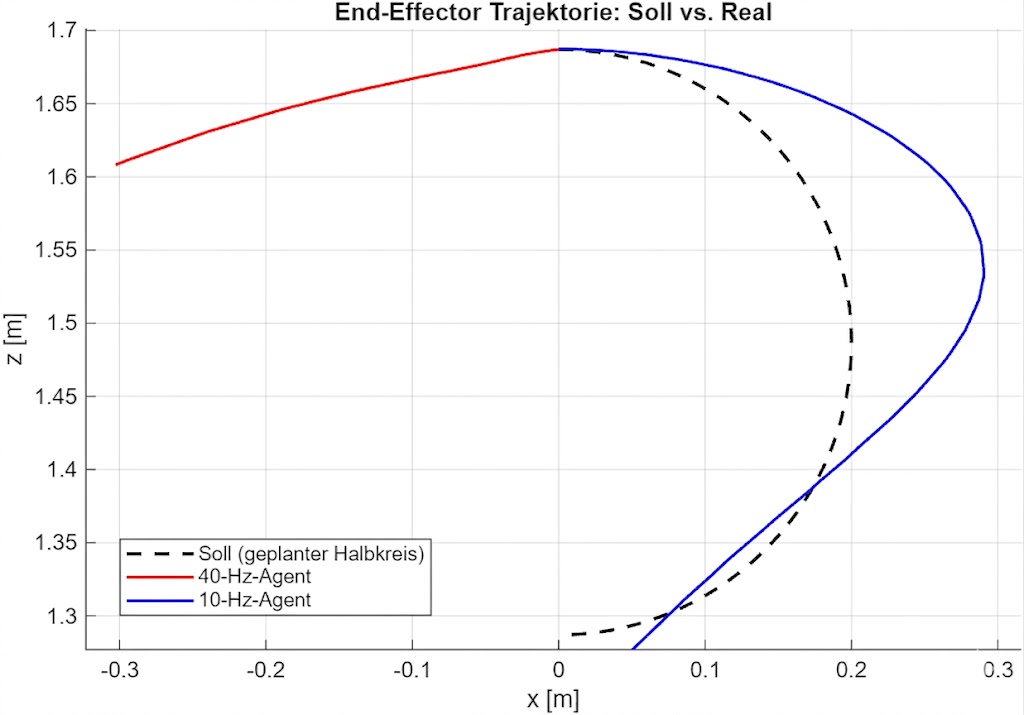
Retraining bei 10 Hz – vollständiger Closed-Loop-Deploy
CDR-2/3/4 aktiv · Bayes-HPO vom 40 Hz-Agenten übernommen (keine erneute BO)
Hardware-Vergleich 40 Hz vs. 10 Hz
Metrik
40 Hz-Agent
10 Hz-Agent
OOD-Abbruch
nach 3,4 s
nein
Schritte (gefahren)
34
74
RMS-Fehler [m]
0,1664
0,0706 (−57 %)
Max.-Fehler [m]
0,4175
0,1351 (−68 %)
Effektive Rate
≈ 9,3 Hz
8,6–8,9 Hz
n ≥ 3 Wiederholungen pro Konfiguration; formale Mehrlauf-Statistik verbleibt als Folgeschritt.
Closed-loop funktional10 Hz-Agent fährt vollständig ohne Sicherheits-Stopp.
Residuale Lücke bleibtObere Bahnabweichung aus Filter-Drift, Reibung und Jitter.
Hardware-Demo
Open-Loop
Closed-Loop 10 Hz
Fazit
Zusammenfassung & Ausblick
Zusammenfassung
Modell & Pipeline
7-DOF-Kinova auf freier Basis in Simulink/Simscape; MotionProfile als gemeinsame Sim-/Real-Signalkette.
RL & Optimierung
PPO dominiert 6/9 KPIs; Bayes-HPO findet LR-Verhältnis Critic:Actor ≈ 17:1.
CDR & Generalisierung
Vier CDR-Features einzeln validiert; CDR-1 halbiert den Trackingfehler auf ungesehener Bahn.
Hardware-Befund
Open-loop millimetergenau; Sample-Rate-Mismatch diagnostiziert; 10 Hz-Retraining fährt die vollständige Trajektorie.
Kernaussage
Die Kombination aus CDR,
identischer Signalkette und
Safety-Stack trägt den Transfer vom Training bis zur Kinova-Hardware.
0,0015 m²PPO-MSE Halfcircle
−49 %CDR-1 OOD-Fehler
1,5–1,6 mmOpen-loop RMS EE
−57 %10 Hz Closed-loop RMS
Offen bleiben residuale Sim-to-Real-Abweichungen, formale Mehrlauf-Statistik und höhere Hardware-Raten über Low-Level-API.
Ausblick & nächste Schritte
⚡
Quantitative Hardware-Auswertung Mehrlauf-Statistik (Mittelwert, Streuung, Konfidenzintervalle) für 40 Hz vs. 10 Hz, vollständige K1–K9 auf Hardware
🔁
Sample-Rate ≥ 40 Hz auf Hardware Wechsel zur Low-Level-UDP-Cyclic-API (1 kHz) und/oder erneute BO für 10 Hz zur Reduktion der residualen Sim-to-Real-Lücke
🔧
HW-Aktivierung CDR-2/3/4 Simscape-Parametrisierung, Integer-Delay-Block und Initial-Condition-Blöcke im Deployment-Modell ergänzen
📊
Quantitative Generalisierung Out-of-Distribution-Stresstests jenseits der Trainingsverteilung (insb. Aktuator-Delays d ≥ 4)
🤏
Kontaktaufgaben Greif- und Andockszenarien mit Kraft-Momenten-Sensorik des Kinova Gen3
🛡️
Formales Shielding & 3D/HIL Runtime-Shield mit temporaler Logik, Bahnen außerhalb der xz-Ebene, HIL-Teststand mit simulierter Mikrogravitation
Vielen Dank!
Fragen & Diskussion
Steven Patrick Ermisch
Frankfurt University of Applied Sciences
Bachelorarbeit · B.Eng. Mechatronik · 1. Mai 2026
 Abb.: On-Orbit-Servicing-Szenario
Abb.: On-Orbit-Servicing-Szenario